
Python=3.7.3 Django=2.2.3 MySQL=5.7 PyMySQL=0.9.3
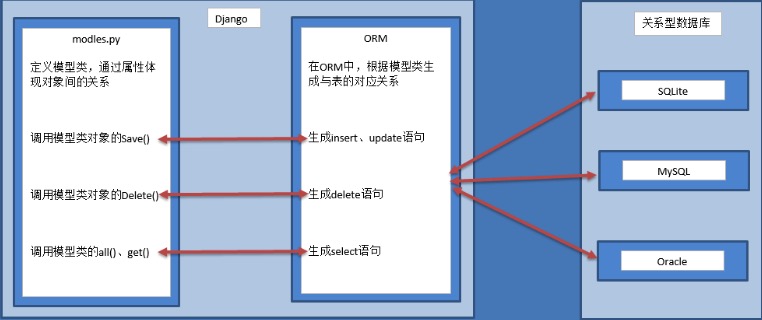
ORM 简介
Object-Relation Mapping,对象-关系映射。
使用 MySQL
在项目的 settings.py 中配置 DATABASES 项:
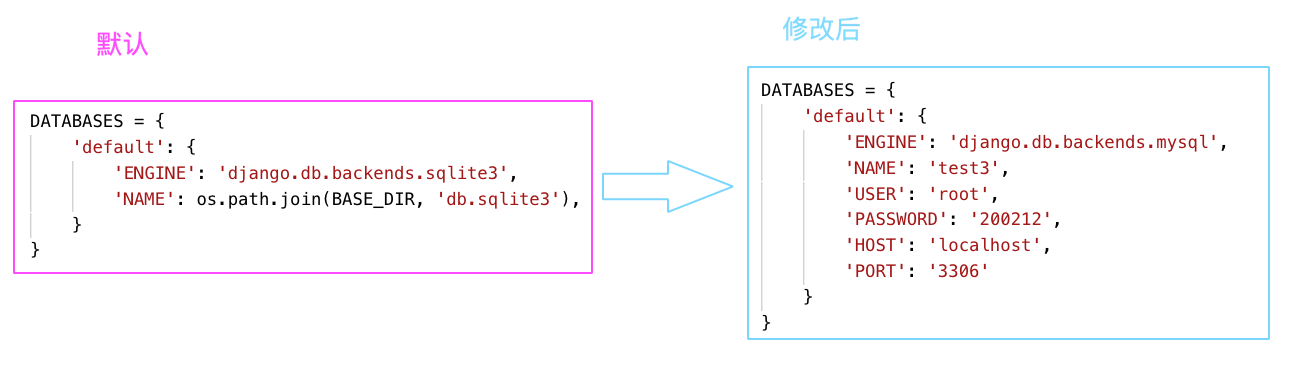
当然光是这些还是不能使用数据库的,还要是用 PyMySQL 来驱动。
使用 pip install pymysql 后,还会有一些版本问题的坑,我碰到了一个,解决方法:https://blog.csdn.net/weixin_33127753/article/details/89100552
模型类
模型类属性命名限制
不能是 Python 的保留字
不能使用连续的下划线,因为 Django 中的查询要用到双下划线
定义属性时要指定字段类型,通过字段类型的参数指定选项,语法如下
1
属性名 = models.字段类型(选项)
字段类型
字段类型在 django.db.models 包中。
| 类型 | 描述 |
|---|---|
| AutoField | 自动增长的 IntegerField,通常不用指定,不指定时 Django 会自动创建属性名为 id 的自动增长属性。 |
| BooleanField | 布尔字段,值为 True 或 False。 |
| NullBooleanField | 支持 Null、True、False 三种值。 |
| CharField(max_length=最大长度) | 字符串。参数 max_length 表示最大字符个数。 |
| TextField | 大文本字段,一般超过 4000 个字符时使用。 |
| IntegerField | 整数。 |
| DecimalField(max_digits=None,decimal_places=None) | 十进制浮点数,参数 max_digits 表示总位。参数 decimal_places 表示小数位数。 |
| FloatField | 浮点数,参数同上。 |
| DateField([auto_now=False,auto_now_add=False]) | 日期。1. 参数 auto_now 表示每次保存对象时,自动设置该字段为当前时间,用于”最后一次修改”的时间戳,它总是使用当前日期,默认为 false。2. 参数auto_now_add表示当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为 false。3. 参数 auto_now_add 和 auto_now 是相互排斥的,组合将会发生错误。 |
| TimeField | 时间,参数同 DateField。 |
| DateTimeField | 日期时间,参数同 DateField。 |
| FileField | 上传文件字段。 |
| ImageField | 继承于 FileField,对上传的内容进行校验,确保是有效的图片。 |
选项
通过选项实现对字段的约束。
| 选项 | 描述 |
|---|---|
| default | 默认值。 |
| primary_key | 若为 True,则该字段会成为模型的主键字段,默认值 False,一般作为 AutoField 的选项使用。 |
| unique | 如果为 True,这个字段在表中必须有唯一值,默认 False。 |
| db_index | 若值为 True,则表中会为此字段创建索引,默认值是 False。 |
| db_column | 字段的名称,如果未指定,则使用属性的名称。 |
| null | 如果为 True,表示允许为空,默认值 False。 |
| blank | 如果为 True,则该字段允许为空白,默认值 False。 |
操作
增
创建个对象,然后给对象的属性赋值,对象.save()。
删
获取要删除的对象,对象.delete()。
改
改嘛,获取到对象,然后赋值再save()。
查
灵魂来了。
查询函数
通过 模型类.objects 可以调用下面的函数,实现对模型类对应的数据表查询。
| 函数名 | 功能 | 返回值 | 说明 |
|---|---|---|---|
| get | 返回表中满足条件的一条并且只能有一条数据。 | 一个模型类对象。 | 参数中写查询条件。1. 如果查询到多条数据,抛异常:MultipleObjectsReturned。2. 查询不到数据,抛异常:DoesNotExist。 |
| all | 返回模型类型对应表中的所有数据。 | QuerySet 类型。 | 查询集。 |
| filter | 返回满足条件的数据集。 | QuerySet 类型。 | 参数写查询条件。 |
| exclude | 返回不满足条件的数据。 | QuerySet类型。 | 参数写查询条件。 |
| order_by | 对查询结果进行排序。 | QuerySet类型。 | 参数中写根据哪些字段进行排序。 |
栗子:
查询图书 id 为 3 的图书信息
1
2BookInfo.objects.get(id=3)
<BookInfo: 笑傲江湖>查询所有图书信息
1
2BookInfo.objects.all()
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>, <BookInfo: test0>, <BookInfo: test1>]>查询图书评论量为 34 的图书信息
1
2BookInfo.objects.filter(bread__gt=34)
<QuerySet [<BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>]>
其他:
判等 exact
查询编号为 1 的图书
1
2
3
4>>> BookInfo.objects.filter(id__exact=1)
<QuerySet [<BookInfo: 射雕英雄传>]>
BookInfo.objects.get(id=1)
<BookInfo: 射雕英雄传>模糊查询 contains、endswith、startswith
查询书名包含’传’的图书
1
2BookInfo.objects.filter(btitle__contains='传')
<QuerySet [<BookInfo: 射雕英雄传>]>查询书名以’部’结尾的图书
1
2BookInfo.objects.filter(btitle__endswith='部')
<QuerySet [<BookInfo: 天龙八部>]>空查询 isnull
查询书名不为空的图书
1
2BookInfo.objects.filter(btitle__isnull=False)
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <BookInfo: 雪山飞狐>, <BookInfo: test0>, <BookInfo: test1>]>范围查询 in
查询 id 为 1 或 2 的图书
1
2BookInfo.objects.filter(id__in=[1, 2])
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>]>比较查询 gt(greate than)、lt(less than)、gte(equal)大于等于、lte小于等于
查询 id 大于 2 的图书
1
2BookInfo.objects.filter(id__gt=2)
<QuerySet [<BookInfo: 笑傲江湖>, <BookInfo: 雪山飞狐>, <BookInfo: test0>, <BookInfo: test1>]>日期查询
查询 1980 年发表的图书
1
2BookInfo.objects.filter(bpub_date__year=1980)
<QuerySet [<BookInfo: 射雕英雄传>]>查询 1980-1-1 日后发表的图书
1
2BookInfo.objects.filter(bpub_date__gt=date(1980,1,1))
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <BookInfo: 雪山飞狐>, <BookInfo: test0>, <BookInfo: test1>]>exclude
查询 id 不为 3 的图书信息
1
2BookInfo.objects.exclude(id=3)
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>, <BookInfo: test0>, <BookInfo: test1>]>order_by
查询所有图书信息,按照 id 从小到大进行排序
1
2BookInfo.objects.all().order_by('id')
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>, <BookInfo: test0>, <BookInfo: test1>]>查询所有图书信息,按照 id 从大到小进行排序
1
2BookInfo.objects.all().order_by('-id')
<QuerySet [<BookInfo: test1>, <BookInfo: test0>, <BookInfo: 雪山飞狐>, <BookInfo: 天龙八部>, <BookInfo: 射雕英雄传>]>把 id 大于 3 的图书信息按阅读量聪大到小排序显示
1
2BookInfo.objects.filter(id__gt=3).order_by('-bread')
<QuerySet [<BookInfo: 雪山飞狐>, <BookInfo: test0>, <BookInfo: test1>]>
F 对象、Q 对象
F 对象用于类属性直线的比较,Q 属性用于查询条件之间的逻辑关系,and/or/not,可以有 &|~ 操作。
首先要导入:from django.db.models import F, Q
F:栗子
查询图书阅读量大于评论量的图书信息
1
2BookInfo.objects.filter(bread__gt=F('bcomment'))
<QuerySet [<BookInfo: 雪山飞狐>]>查询图书阅读量大于 2 倍评论量的图书信息
1
2BookInfo.objects.filter(bread__gt=F('bcomment')*2)
<QuerySet [<BookInfo: 雪山飞狐>]>
Q:栗子
查询 id 大于 3 且阅读量大于 30 的图书信息
1
2
3
4BookInfo.objects.filter(id__gt=3, bread__gt=30)
<QuerySet [<BookInfo: 雪山飞狐>]>
BookInfo.objects.filter(Q(id__gt=3) & Q(bread__gt=30))
<QuerySet [<BookInfo: 雪山飞狐>]>查询 id 大于 3 或者阅读量大于 30 的图书信息
1
2BookInfo.objects.filter(Q(id__gt=3) | Q(bread__gt=30))
<QuerySet [<BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>, <BookInfo: test0>, <BookInfo: test1>]>查询 id 不等于 3 的图书信息
1
2BookInfo.objects.filter(~Q(id__gt=3))
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>]>
聚合函数
sum、count、avg、max、min
aggregate:调用这个函数来使用聚合,返回值是一个字典。
首先需要导入聚合函数:from django.db.models import Sum, Count, Max, Min, Avg
栗子:
查询所有图书的数量
1
2BookInfo.objects.all().aggregate(Count('id'))
{'id__count': 5}查询所有图书阅读量的总和
1
2BookInfo.objects.aggregate(Sum('bread'))
{'bread__sum': 126}
count 函数返回一个数字,统计满足条件数据的数量。
栗子:
统计所有图书的数量
1
2
3
4
5BookInfo.objects.all().count()
5
BookInfo.objects.count()
6
"""这里不同是因为我的objects对象的all方法是自定义的,返回了isDelete=False的结果"""统计 id 大于 3 的所有图书的树木
1
2BookInfo.objects.filter(id__gt=3).count()
3
查询集
all、filter、exclude、order_by 调用这些函数会产生一个查询集,QuerySet 类对象可以继续调用上面的所有函数。
查询集的特性:
- 惰性查询:只有在实际使用查询集中的数据的时候才会发生对数据库的整整查询
- 缓存:当使用的是同一个查询集时,第一次使用的时候会发生实际数据库的查询,然后把结果缓存起来,之后再使用这个查询集时,使用的是缓存中的结果。
限制查询集:
可以对一个查询集进行_取下标或者切片_操作来限制查询集的结果。
对一个查询集进行切片操作会差生一个新的查询集,【下标不允许为负数】。
取出查询集第一条数据的两种方式:
| 方式 | 说明 |
|---|---|
| b[0] | 如果不存在,会抛出 IndexError 异常。 |
| b[0:1].get() | 如果不存在,会抛出 DoesNotExist 异常。 |
exists:判断一个查询集中是否由数据,True/False。
关联查询(一对多)
查询和对象关联的数据:
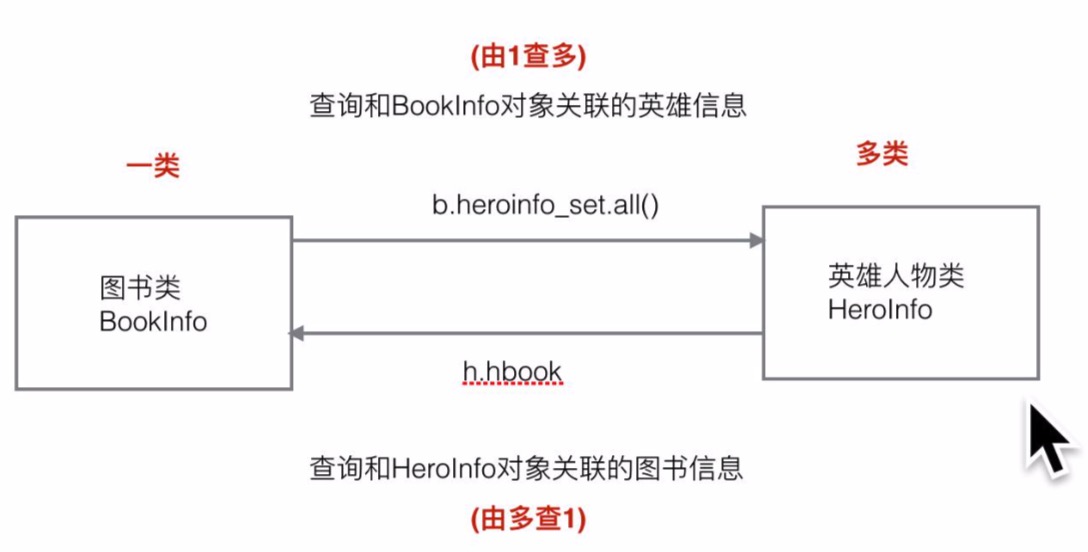
通过模型类实现关联查询:
【注意】
- 通过模型类实现关联查询时,要查哪个表中的数据,就需要通过哪个类来查。
- 写关联查询条件的时候,如果类中没有关系属性,条件需要写对应类的名,如果类中有关系属性,直接写关系属性。
通过多类的条件查询一类的数据:一类名.objects.filter(多类名小写__多类属性名__条件名)
通过一类的条件查询多类的数据:多类名.objects.filter(关联属性__一类属性名__条件名)
栗子:
查询图书中关联的英雄描述包含‘八’
1
2BookInfo.objects.filter(heroinfo__hcomment__contains='八')
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>]>查询图书信息中英雄 id 大于 3
1
2BookInfo.objects.filter(heroinfo__id__gt=3)
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 射雕英雄传>, <BookInfo: 射雕英雄传>, <BookInfo: 射雕英雄传>, <BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 天龙八部>, <BookInfo: 天龙八部>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <BookInfo: 笑傲江湖>, <BookInfo: 笑傲江湖>, <BookInfo: 笑傲江湖>, <BookInfo: 雪山飞狐>, <BookInfo: 雪山飞狐>, <BookInfo: 雪山飞狐>, <BookInfo: 雪山飞狐>]>查询书名为“天龙八部”的所有英雄
1
2HeroInfo.objects.filter(hbook__btitle='天龙八部')
<QuerySet [<HeroInfo: 乔峰>, <HeroInfo: 段誉>, <HeroInfo: 虚竹>, <HeroInfo: 王语嫣>]>
模型类关系
一对多
栗:图书类 - 英雄类,models.ForeignKey() 定义在多类中。
多对多
栗:新闻类 - 新闻类型类(体育新闻、国际新闻),models.ManyToManyField() 定义在哪个类都行。
一对一
栗:员工基本信息类 - 员工详细信息类,models.OneToOneField() 定义在哪个类都行。
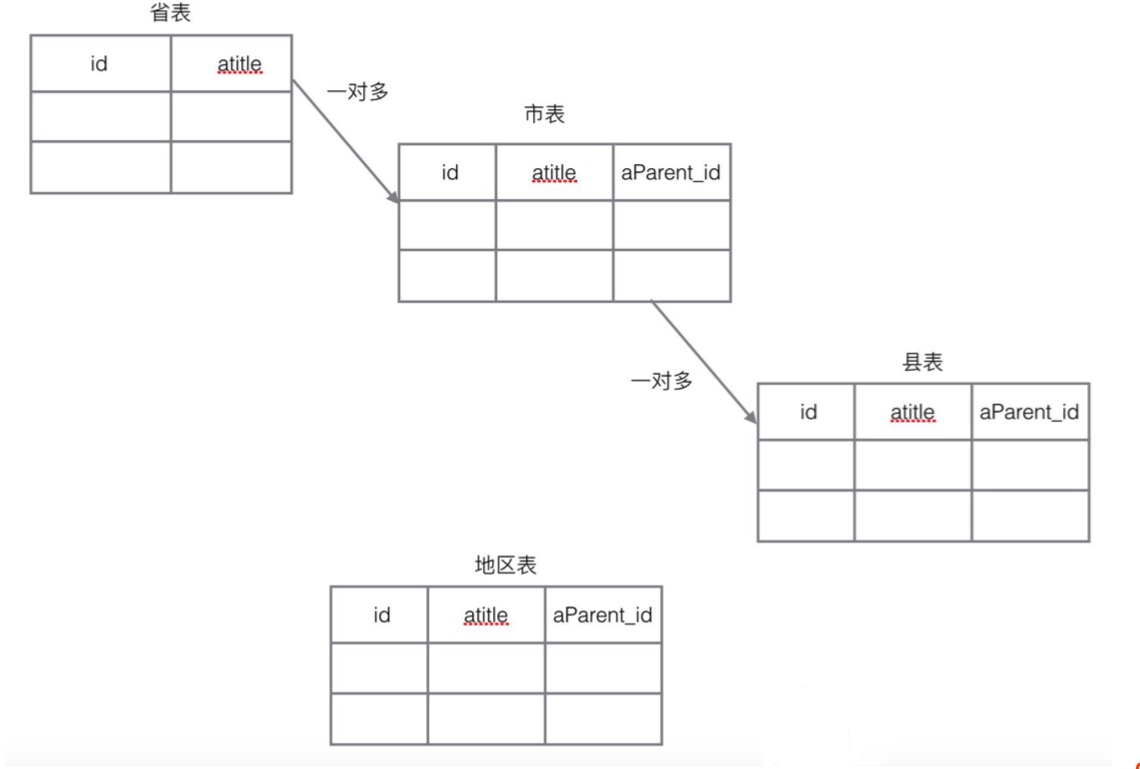
自关联
自关联是一种特殊的一对多的关系。
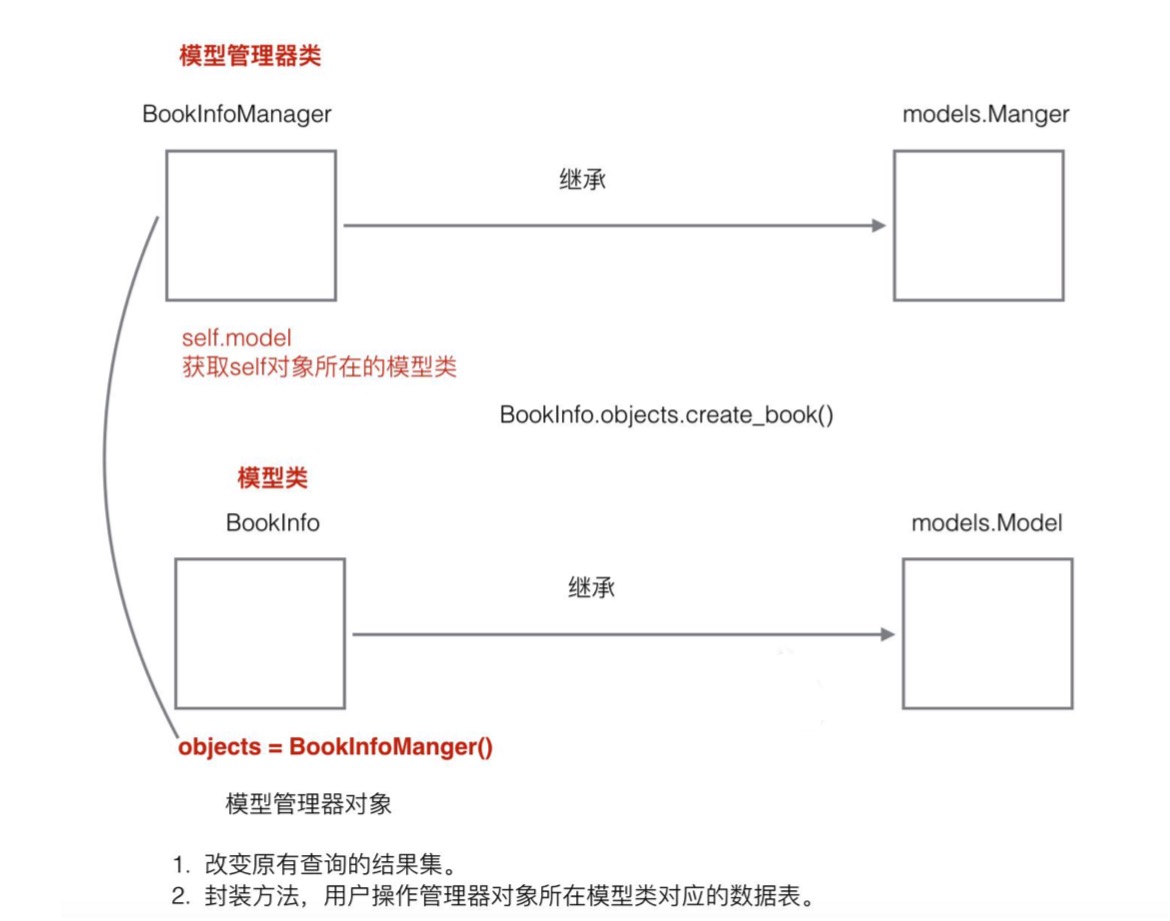
自定义管理器
BookInfo.objects.all() 中的 objects 是一个什么东西呢?
objects 是 Django 自动生成的管理器对象,通过这个管理器可以实现对数据的查询。
objects 是 models.Manger 类的一个对象。
自定义管理器之后 Django 不再生成默认的 objects 管理器。
自定义模型管理器类
自定义一个管理器类,继承自 models.Manger 类,再在具体的模型类里定义一个自定义管理器类的对象。
应用场景:
改变查询的结果集
比如调用 BookInfo.objects.all() 返回的是 isDelete=True 的图书的数据。
添加额外的方法
管理器类中定义一个方法,帮助我们操作模型类对应的数据表。
使用 self.model 就可以创建一个跟自定义管理器对应的模型类对象(解耦)。
like this:
1 | # yourapp.models.py |
元选项
Django 默认生成的表名:应用名小写_模型类名小写
元选项需要在模型类中定义一个元类 Meta,在里面定义一个类属性 db_table 就可以指定表名。

