
描述进程
进程信息被放在一个叫做进程控制块(PCB,process control block)的数据结构中,可以理解为进程属性的集合。
Linux 下的 PCB 是 task_struct,GitHub 上 Linux 源码的 /include/linux/sched.h 中。
关于 task_struct 详细一些的中文资料可以参看:task_struct 数据结构
task_struct 的内容
标识符:唯一的标识一个进程,PID;
状态:任务状态、进程退出码、退出信号等;
优先级:现对于其他进程的优先级;
程序计数器:程序中即将被执行的下一条指令的地址;
内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针;
上下文数据:进程执行时处理器的寄存器中的数据;
保存上下文:CPU 寄存器的内容保存到内存中;
恢复上下文:从内存中读入寄存器的值。
I/O 信息:包括显示的 I/O 请求,分配给进程的 I/O 设备和被进程使用的文件列表;
记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等;
其他信息。
组织进程
在Linux系统中,所有运行在系统里的进程都是 task_struct 链表(双向链表)的形式存在内核里。
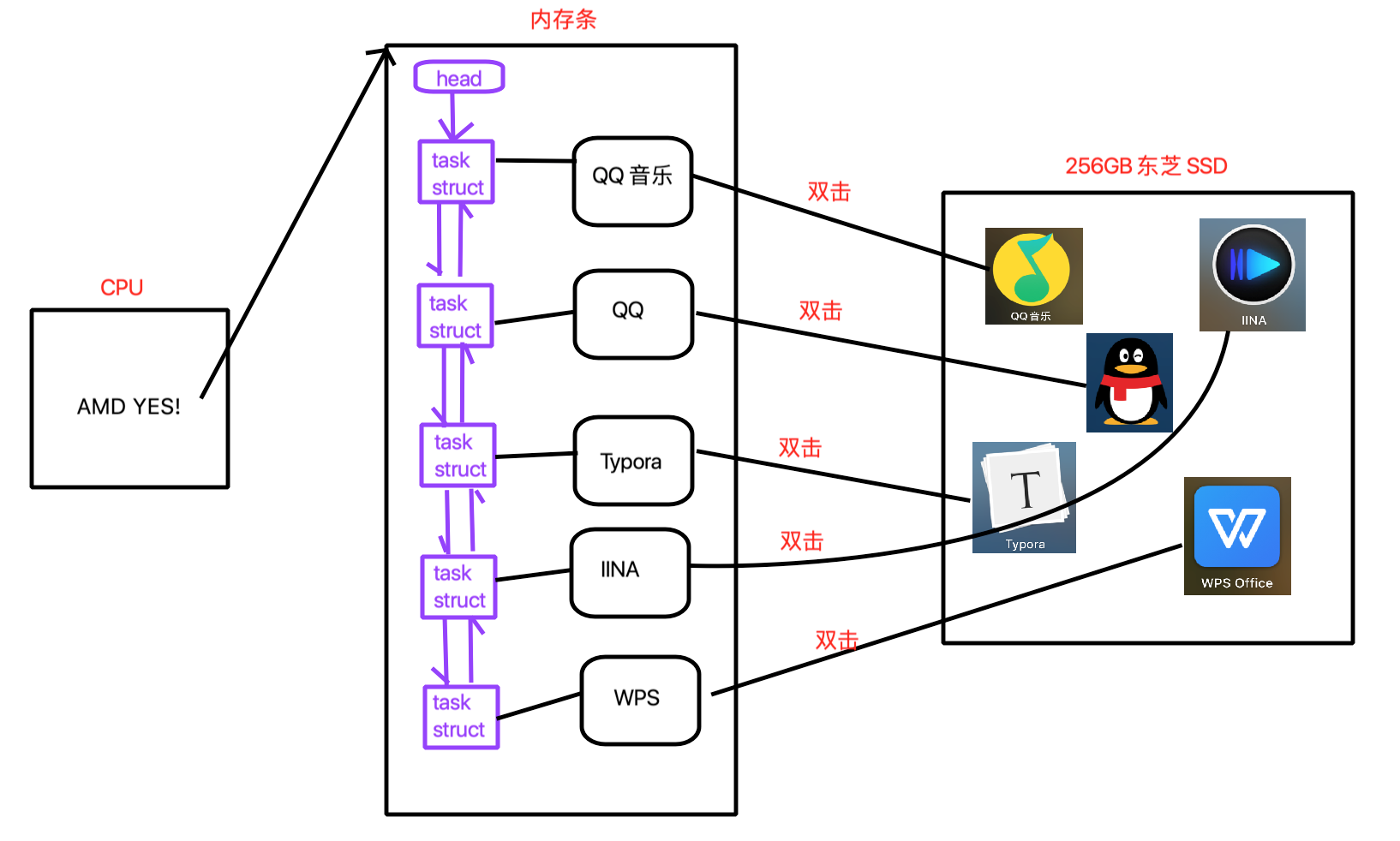
查看进程
在 Linux 下可以在 /proc 中查看到文件形式的进程。
也可以通过 ps、top 命令查看进程。
进程状态
1 | /* |
Running 运行状态,表明进程要么在运行中要么在运行队列里,并不意味着一定在运行中;
Sleeping 睡眠状态 TASK_INTERRUPTIBLE,意味着进程在等待事件完成;
Disk sleep 磁盘休眠状态 TASK_UNINTERRUPTIBLE,有时候也叫不可中断睡眠状态或深度睡眠状态,在这个状态的进程通常会等待 IO 结束,一般在密集的进行 IO 操作的时候会出现,程序在临死前吐 core dump 就会出现 D 状态;
T stopped 停止状态,可以通过发送 SIGSTOP 信号来停止进程,这个被暂停的进程可以通过发送 SIGCONT 信号让其继续运行(ctrl + z挂起,fg 再回来);
tracing stop 跟踪状态,在 GDB 调试的时候出现;
Zombie 僵尸状态,僵尸进程的特征;
X dead 死亡状态,进程结束,只在源码中可以看到。
上面这些状态在 Linux 内核源码中可以看到定义,在操作系统调度进程的过程中进程有三种基本状态:运行、阻塞、就绪。(还有一些资料有说三态模型、五态模型、七态模型)
僵尸进程
子进程结束后,父进程没有回收子进程的资源。

僵尸进程的危害:
进程的退出状态必须被维持下去,因为他要告诉关心它的进程(父进程),你交给我的任务,我办的怎么样了。这样就会导致一些数据需要一直被维护着,造成内存资源的浪费,内存泄漏。
避免产生僵尸进程:
- 进程等待(wait、waitpid)
- fork 两次避免僵尸进程
孤儿进程
父进程结束,但是子进程还未结束,子进程就成为了一个孤儿进程,由 init 进程收养并回收。

进程调度
不同类型的操作系统中进程调度的算法是不同的。
批处理系统常用调度算法:
①、先来先服务:FCFS
②、最短作业优先
③、最短剩余时间优先
④、响应比最高者优先
分时系统调度算法:
①、轮转调度
②、优先级调度
③、多级队列调度
④、彩票调度
实时系统调度算法:
①、单比率调度
②、限期调度
③、最少裕度法
进程的优先级
进程的优先级在操作系统中通常用于进程的调度。
top 命令可以查看当前系统上运行的进程信息,其中 PR 那一列就是对应进程的优先级。
在 Linux 中 PR 越小优先级越高,NI(nice) 表示修正值,最终系统认定的优先级是 PR + NI。
通过指令可以调整 nice 值,但是宏观一般看不出太大效果。
top 进入后按 r 输入进程 PID 输入 nice 值。
进程地址空间
栈有多大?
测试方法:开数组进程测试
栈空间 8MB,由于被其他东西占用了一部分,所以不到 8MB。栈的大小是可以通过 ulimit 设置的。
堆有多大?
非常大~~~
32 位系统:4GB,上限取决于内存条(钱),如果是 16 GB 电脑,堆可能有 10 多GB。
什么时候用栈?什么时候用堆?
如果是小对象,并且需要频繁创建和销毁,推荐在栈上分配。
栈上分配内存更高效(esp寄存器的修改,esp-4);
堆上分配内存就很复杂了,查阅malloc底层实现;
如果是大对象,必须在堆上分配。
如果是很大的对象又要频繁使用那怎么办?
内存池!!
(类似的有进程池、线程池、数据库连接池……)
EOF

