
Docker 是一个使用 Linux Namespace 和 Cgroups 的虚拟化工具。
Linux Namespace 和 Cgroups 是什么?有什么用?在 Docker 中是怎么被使用的?
Linux Namespace
基本概念
Linux Namespace 是 Kernel 的一个功能,它可以隔离一系列的系统资源(ProcessID、UserID、Network)。
PID 映射关系图:
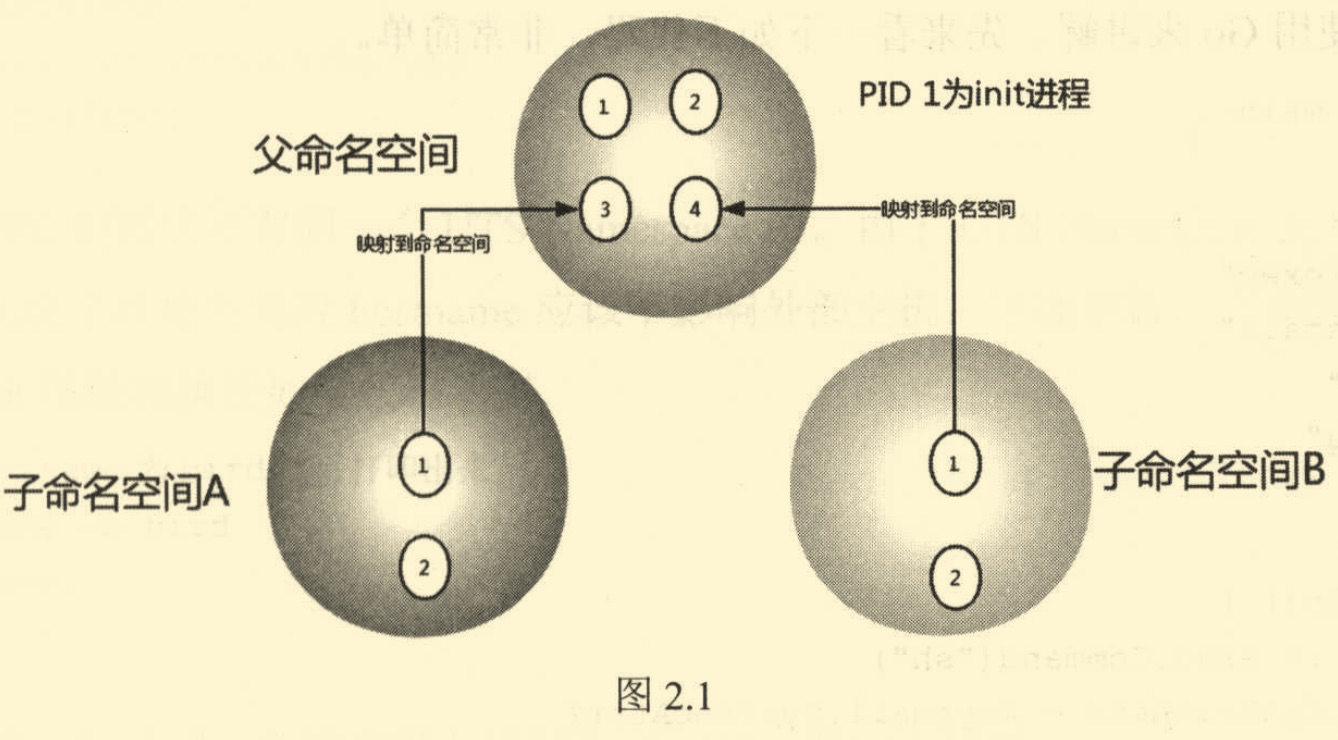
当前 Linux 一共实现了 6 种不同类型的 Namespace。
| Namespace类型 | 系统调用参数 | 内核版本 | 功能说明 |
|---|---|---|---|
| Mount Namespace | CLONE_NEWNS | 2.4.19 | 磁盘挂载点和文件系统的隔离能力 |
| UTS Namespace | CLONE_NEWUTS | 2.6.19 | 主机名隔离能力 |
| IPC Namespace | CLONE_NEWIPC | 2.6.19 | 进程间通信的隔离能力 |
| PID Namespace | CLONE_NEWPID | 2.6.24 | 进程隔离能力 |
| Network Namespace | CLONE_NEWNET | 2.6.29 | 网络隔离能力 |
| User Namespace | CLONE_NEWUSER | 3.8 | 用户隔离能力 |
Namespace 的 API 主要使用如下 3 个系统调用:
- clone() 创建新进程。根据系统调用参数来判断哪些类型的 Namespace 被创建,而且它们的子进程也会被包含到这些 Namespace 中。
- unshare() 将进程移除某个 Namespace。
- setns() 将进程加入到 Namespace 中。
UTS Namespace
UTS Namespace 主要用来隔离 nodename 和 domainname 两个系统标识。
在 UTS Namespace 里面,每个 Namespace 允许有自己的 hostname。
1 |
|
该程序骨架调用 clone() 函数实现了子进程的创建工作,并定义子进程的执行函数,clone() 第二个参数指定了子进程运行的栈空间大小,第三个参数即为创建不同 namespace 隔离的关键。
对于 UTS namespace,传入 CLONE_NEWUTS,如下:
1 | int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS, NULL); |
为了能够看出容器内和容器外主机名的变化,我们子进程执行函数中加入:
1 | sethostname("container", 9); |
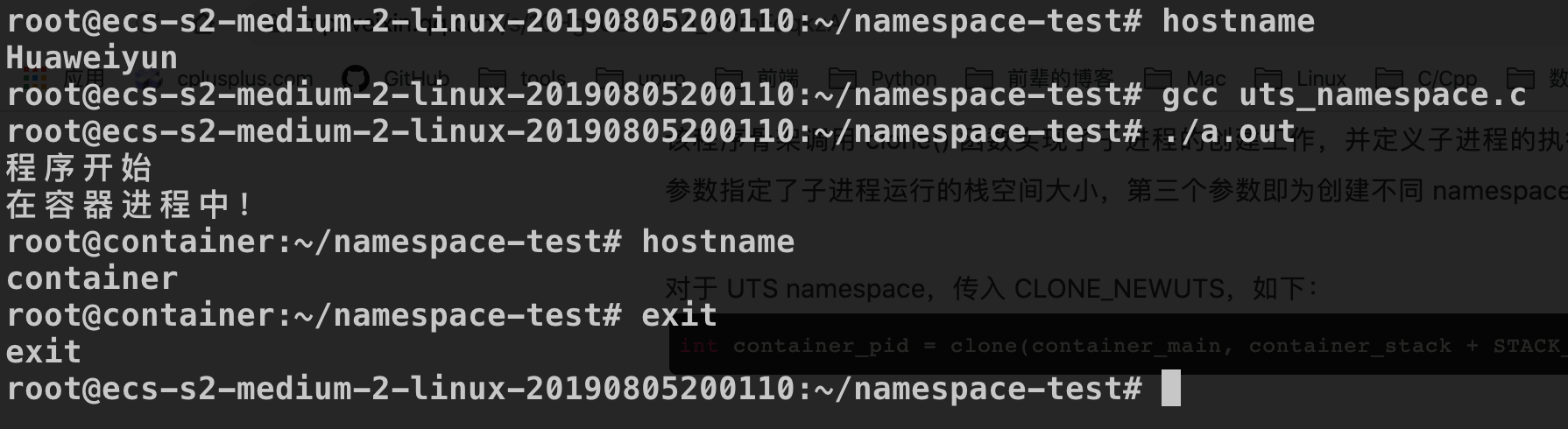
相关 Linux 命令:
1 | hostname # 查看 |
IPC Namespace
IPC Namespace 用来隔离 System V IPC 和 POSIX message queues。(隔离进程间通信)
代码只需要修改一下 clone 的参数即可:
1 | int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS | CLONE_NEWIPC, NULL); |
效果:
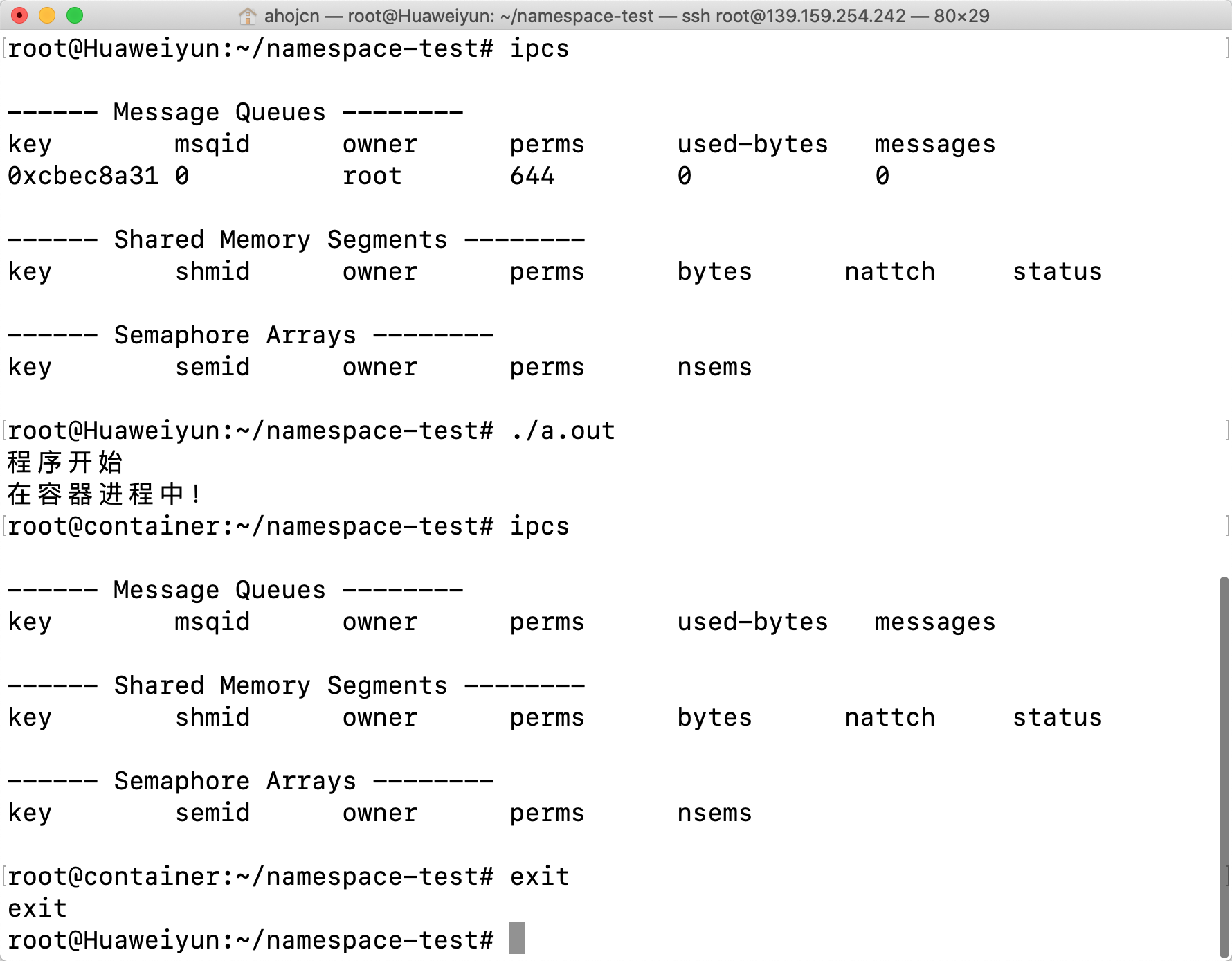
相关 Linux 命令:
1 | ipcs -q # 查看现有的 ipc message queues |
PID Namespace
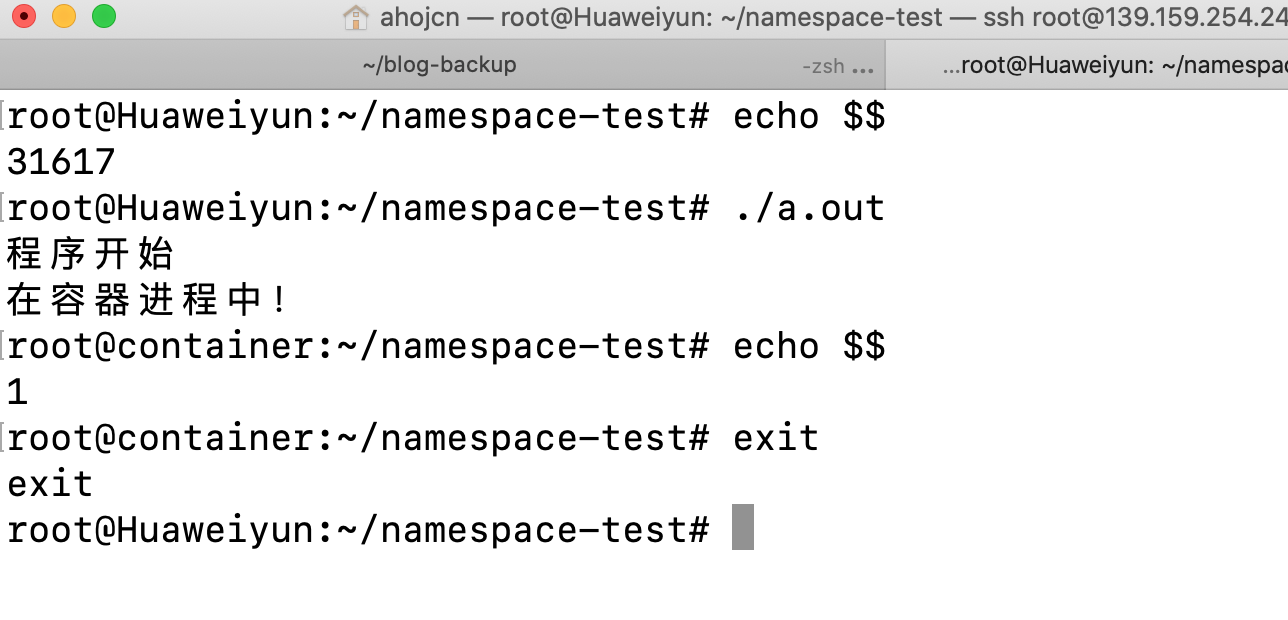
PID Namespace 是用来隔离进程 ID 的。
1 | int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWPID, NULL); |
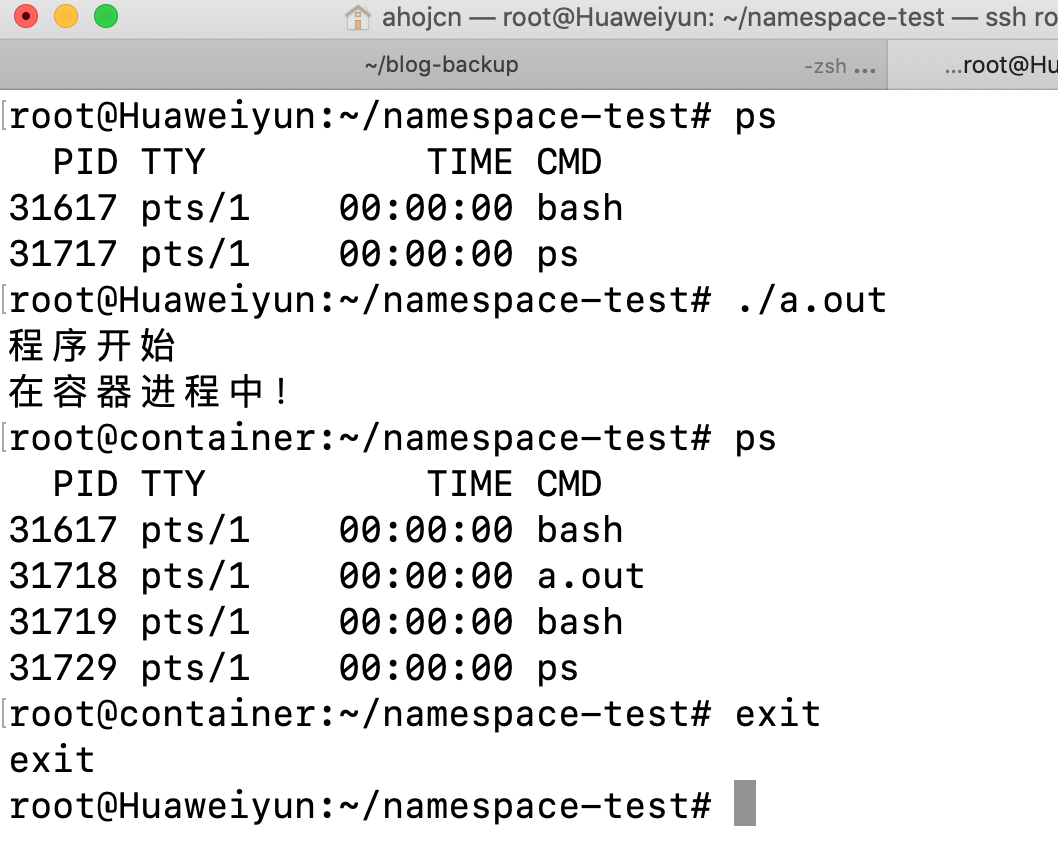
效果:PID 号,发生了变化;但是 ps 之类的没有发生变化。
原因是 ps/top 之类的命令底层调用的是文件系统的 /proc 文件内容,由于 /proc 文件系统(procfs)还没有挂载到一个与原 /proc 不同的位置,自然在容器中显示的就是宿主机的进程。
在容器中重新挂载 /proc 即可实现隔离:
mount -t proc proc /proc。这种方式会破坏 root namespace 中的文件系统,当退出容器时,如果 ps 会出现错误,只有再重新挂载一次 /proc 才能恢复。
一劳永逸地解决这个问题最好的方法就是用 mount namespace。
相关 Linux 命令:
1 | echo $$ # 输出当前 shell pid |
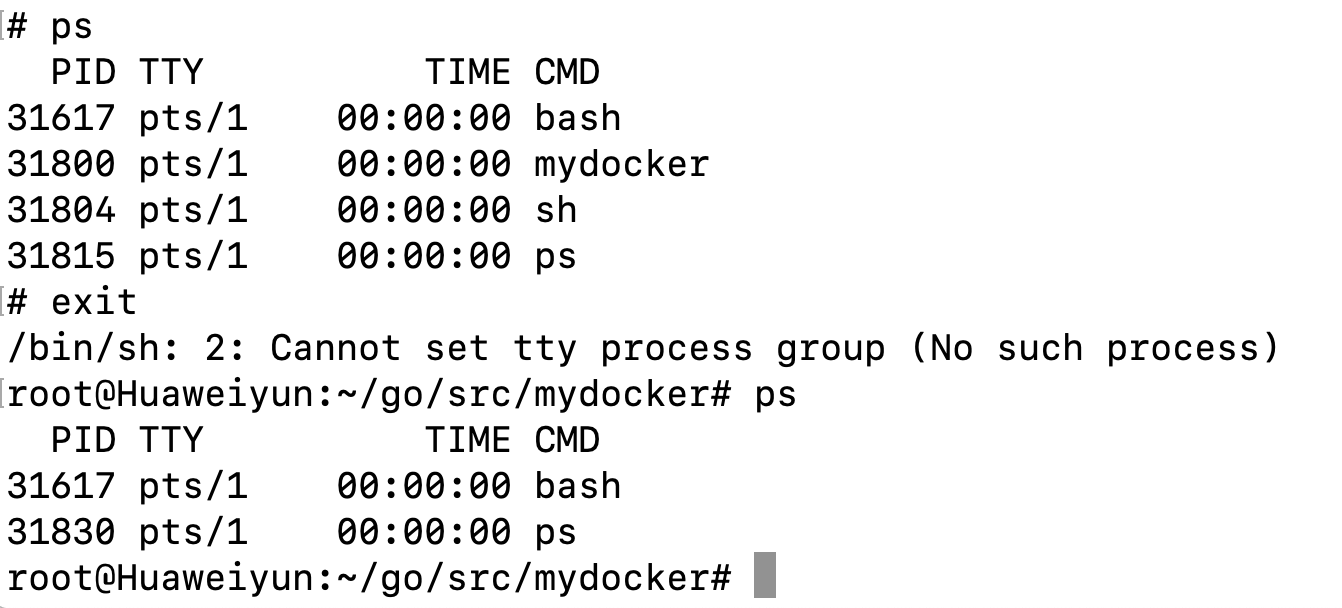
Mount Namespace
通过隔离文件系统挂载点对隔离文件系统提供支持,它是历史上第一个Linux namespace,所以它的标识位比较特殊,就是CLONE_NEWNS。
CLONE_NEWNS:New Namespace 的缩写,当时的人们貌似没有意识到,以后还会有很多类型的 Namespace 加入 Linux 家庭。
1 | int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWPID | CLONE_NEWNS, NULL); |
注意内核版本问题导致的退出容器后需要重新挂载,参考:
https://github.com/xianlubird/mydocker/issues/41
效果如下:实现了 ps / top 等的隔离。
相关 Linux 命令:
1 | ps |
User Namespace
主要隔离了安全相关的标识符和属性,包括用户 ID、用户组 ID、root 目录、key 以及特殊权限。
简单说,就是一个普通用户的进程通过 clone() 之后在新的 user namespace 中可以拥有不同的用户和用户组,比如可能是超级用户。
同样,可以加入 CLONE_NEWUSER 参数来创建一个 User namespace。然后再子进程执行函数中加入 getuid() 和 getpid() 得到 namespace 内部的 User ID。
相关 Linux 命令:
1 | id # 查看用户相关信息 |
Network Namespace
Network namespace 实现了网络资源的隔离,包括网络设备、IPv4 和 IPv6 协议栈,IP 路由表,防火墙,/proc/net 目录,/sys/class/net 目录,套接字等。
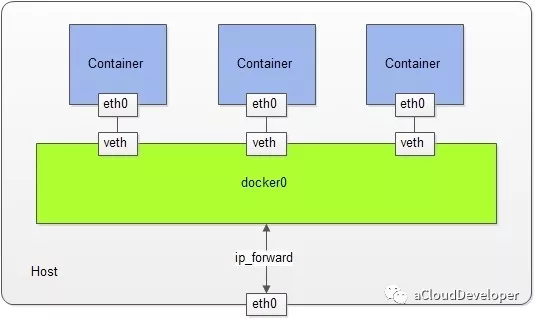
Network Namespace 可以让每个容器拥有自己独立的(虚拟的)网络设备,而且容器内的应用可以绑定到自己的端口,每个 Namespace 内的端口都不会互相冲突。在宿主机上搭建网桥之后,就能很方便的实现容器之间的通信,而且不同容器上的应用可以使用相同的端口。
Network namespace 不同于其他 namespace 可以独立工作,要使得容器进程和宿主机或其他容器进程之间通信,需要某种“桥梁机制”来连接彼此(并没有真正的隔离),这是通过创建 veth pair (虚拟网络设备对,有两端,类似于管道,数据从一端传入能从另一端收到,反之亦然)来实现的。当建立 Network namespace 后,内核会首先建立一个 docker0 网桥,功能类似于 Bridge,用于建立各容器之间和宿主机之间的通信,具体就是分别将 veth pair 的两端分别绑定到 docker0 和新建的 namespace 中。
Linux Cgroups
Linux Cgroups(Control Groups)提供了对一组进程及将来子进程的资源限制、控制和统计的能力。
这些组员包括:CPU、内存、存储、网络等。
通过 Cgroups,可以方便地限制某个进程资源占用,并且可以实时监控进程的监控和统计信息。
Cgroups 的 3 个组件:
cgroup:是对进程分组管理的一种机制,一个 cgroup 包含一组进程,并可以在这个 cgroup 上增加 Linux subsystem 的各种参数配置,将一组进程和一组 subsystem 的系统参数关联起来。
subsystem:是一组资源控制的模块,一般包含如下几项:
blkio 设置对块设备(比如硬盘)输入输出的访问控制。
cpu 设置 cgroup 中进程的 CPU 被调度的策略。
cpuacct 可以统计 cgroup 中进程的 CPU 占用。
cpuset 在多核机器上设置 cgroup 中进程可以使用的 CPU 和内存(此处内存仅用于 NUMA 架构)
devices 控制 cgroup 中进程对设备的访问。
freezer 用于挂起(suspend)和恢复(resume)cgroup 中的进程。
memory 用于控制 cgroup 中进程的内存占用。
net_cls 用于将 cgroup 中进程产生的网络包分类,以便 Linux 的 tc(traffic controller)可以根据分类区分出来自某个 cgroup 的包并做限流或监控。
net_prio 设置 cgroup 中进程产生的网络流量的优先级。
ns 这个 subsystem 比较特殊,它的作用是使 cgroup 中的进程在新的 Namespace 中 fork 新进程(NEWNS)时,创建出一个新的 cgroup,这个 cgroup 包含新的 Namespace 中的进程。
每个 subsystem 会关联到定义了相应限制的 cgroup 上,并对这个 cgroup 中的进程做相应的限制和控制。这些 subsystem 是逐步合并到内核中的,如何看到当前的内核支持哪些 subsystem 呢?可以安装 cgroup 的命令行工具
apt-get install cgroup-bin,然后通过lssubsys -a看到 Kernel 支持的 subsystem。hierarchy 的功能是把一组 cgroup 串成一个树状的结构,一个这样的树便是一个 hierarchy,通过这种树状结构,Cgroups 可以做到继承。
三个组件相互的关系:
- 系统在创建了新的 hierarchy 之后,系统中所有的进程都会加入这个 hierarchy 的 cgroup 根节点,这个 cgroup 根节点是 hierarchy 默认创建的。
- 一个 subsystem 只能附加到一个 hierarchy 上面。
- 一个 hierarchy 可以附加多个 subsystem。
- 一个进程可以作为多个 cgroup 的成员,但是这些 cgroup 必须在不同的 hierarchy 中。
- 一个进程 fork 处子进程时,子进程是和父进程在同一个 cgroup 中的,也可以根据需要将其移动到其他 cgroup 中。
Kernel 为了使对 Cgroups 的配置更直观,是通过一个虚拟的树状文件系统配置 Cgroups,通过层级的目录虚拟出 cgroup 树。
栗子:
创建并挂在一个 hierarchy(cgroup 树),如下:
1
2
3mkdir cgroup-test # 创建一个 hierarchy 挂载点
sudo mount -t cgroup -o none,name=cgroup-test cgroup-test ./cgroup-test # 挂在一个 hierarchy
ls ./cgroup-test # 挂在后可以看到系统在这个目录下生成了一些默认文件这些文件就是这个 hierarchy 中 cgroup 根节点的配置项,文件含义分别如下:
- cgroup.clone_children:cpuset 的 subsystem 会读取这个配置文件,如果这个值是 1(默认是 0),子 cgroup 才会继承父 cgroup 的 cpuset 的配置。
- cgroup.procs:树种当前节点 cgroup 中的进程组 ID,现在的位置是在根节点,这个文件中会有现在系统中所有进程组的 ID。
- notify_on_release 和 release_agent 会一起使用。notify_on_release 标识当这个 cgroup 最后一个进程退出的时候是否执行了 release_agent;release_agent 则是一个路径,通常用作进程退出之后自动清理掉不再使用的 cgroup。
- tasks:标识该 cgroup 下面的进程 ID,如果把一个进程 ID 写到 tasks 中,便会将相应的进程加入到这个 cgroup 中。
然后在 cgroup-test 上 cgroup 根节点中扩展出的两个子 cgroup:
1
2
3在 cgroup-test 文件夹下
mkdir cgroup-1 # 创建子 cgroup cgroup-1
mkdir cgroup-2 # 创建子 cgroup cgroup-2在一个 cgroup 目录下创建文件夹时,Kernel 会把文件夹标记为这个 cgroup 的子 cgroup,他们会继承父 cgroup 的属性。
在 cgroup 中添加和移动进程。
一个进程在一个 Cgroups 的 hierarchy 中,只能在一个 cgroup 节点上存在,系统的所有进程都会默认在根节点上存在,可以将进程移动到其他 cgroup 节点,只需要将进程 ID 写到移动到的 cgroup 节点的 tasks 文件中即可。
1
2
3在 cgroup-1 文件夹下
sh -c "echo $$ >> tasks" # 将现在所在的终端移动到 cgroup-1中
cat /proc/${$$}/cgroup # 可以看到所属 cgroup通过 subsystem 限制 cgroup 中进程的资源。
在上面创建 hierarchy 的时候,这个 hierarchy 并没有关联到任何 subsystem,所以没办法通过那个 hierarchy 中的 cgroup 节点限制进程的资源占用,其实系统默认已经为每个 subsystem 创建了一个默认的 hierarchy,比如 memory 的 hierarchy。
1
mount | grep memory # 可以看到目录的挂在情况
下面通过在这个 hierarchy 中创建 cgroup,限制如下进程占用的内存。
1
2
3
4
5
6
7
8
9
10首先在不做限制的情况下,启动一个占用内存的 stress 进程
stress --vm-bytes 200m --vm-keep -m 1
创建一个 cgroup
mkdir test-limit-memory && cd test-limit-memory
设置最大 cgroup 的最大内存占用为 100MB
sh -c "echo "100m" > memory.limit_in_bytes"
将当前进程移动到这个 cgroup 中
sh -c "echo $$ > tasks"
再次运行占用内存 200MB 的 stress 进程
stress --vm-bytes 200m --vm-keep -m 1
参考:
《自己动手写 Docker》
https://blog.csdn.net/liumiaocn/article/details/52549659
https://mp.weixin.qq.com/s/10HgkUE14wVI_RNmFdqkzA
https://github.com/xianlubird/mydocker/issues/41
未完,EOF

