
问题引入:在容器中执行 top 查看 CPU 使用情况,top user space 却显示 58.5%(12core * 58.5% ≈ 7core),但容器中实际两个进程 200% %CPU 只占用了 2core。
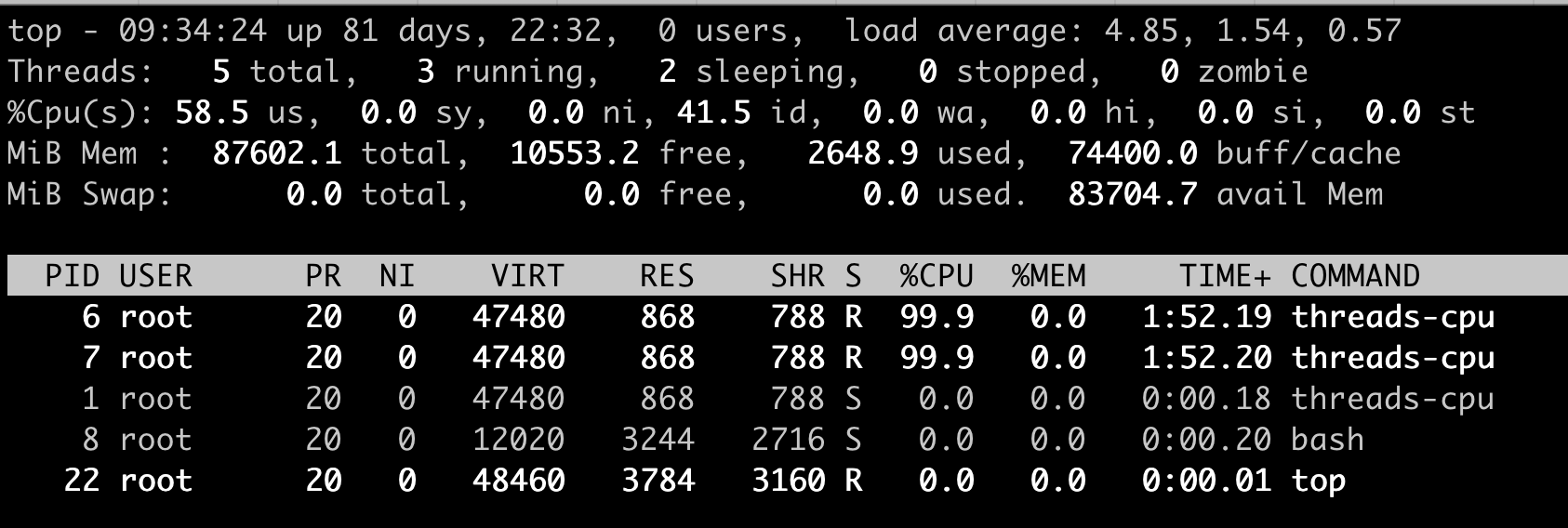
如何正确得到容器的 CPU 开销?
top 命令输出结果
0.0 us, 0.0 sy, 0.0 ni, 99.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
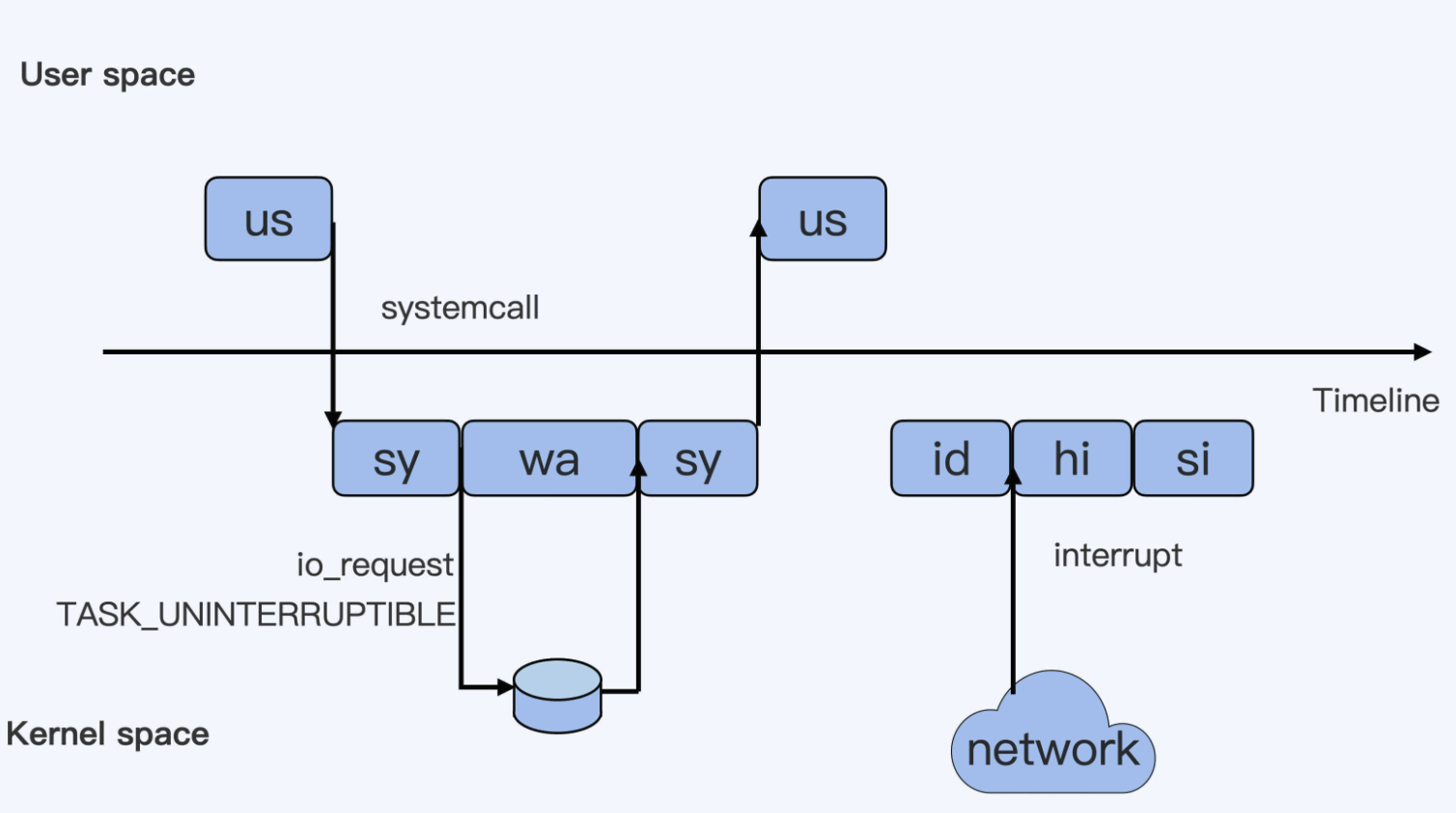
- us(user)用户态 CPU 使用,普通用户程序代码只要不调用系统调用(system call),这些代码的消耗就属于 us
- sy(system)内核态 CPU 使用,当用户代码中使用
read()读取文件时这个用户进程就会从用户态切换到内核态,内核态read()在读到真正的文件前还会进行一些文件系统层的操作,这些消耗就属于 sy - wa(iowait)进程在进行读文件的时候会被设置成
TASK_UNINTERRUPTIBLE状态,这段等待 I/O 的时间标记为 wa,磁盘返回数据时进程在内核态拿到数据处于 sy - id(idle)空闲状态
- hi(hardware irq)机器在收到一个网络数据包,网卡会发送一个中断(interrupt),CPU 响应中断后进入中断处理程序,中断处理程序需要关闭中断,所以这个硬中断时间不能太长
- si(soft irq)软中断来完成一些耗时比较长的工作,从网卡收数据包的大部分工作都是由软终端来处理
无论是 hi 还是 si 他们在处理的时候不属于任何一个进程。
- ni(nice)优先级,正值 1-19
- st(steal)是在虚拟机里用的一个 CPU 使用类型,表示有多少时间是被同一个宿主机上的其他虚拟机抢走的
CPU CGroup 是如何工作的
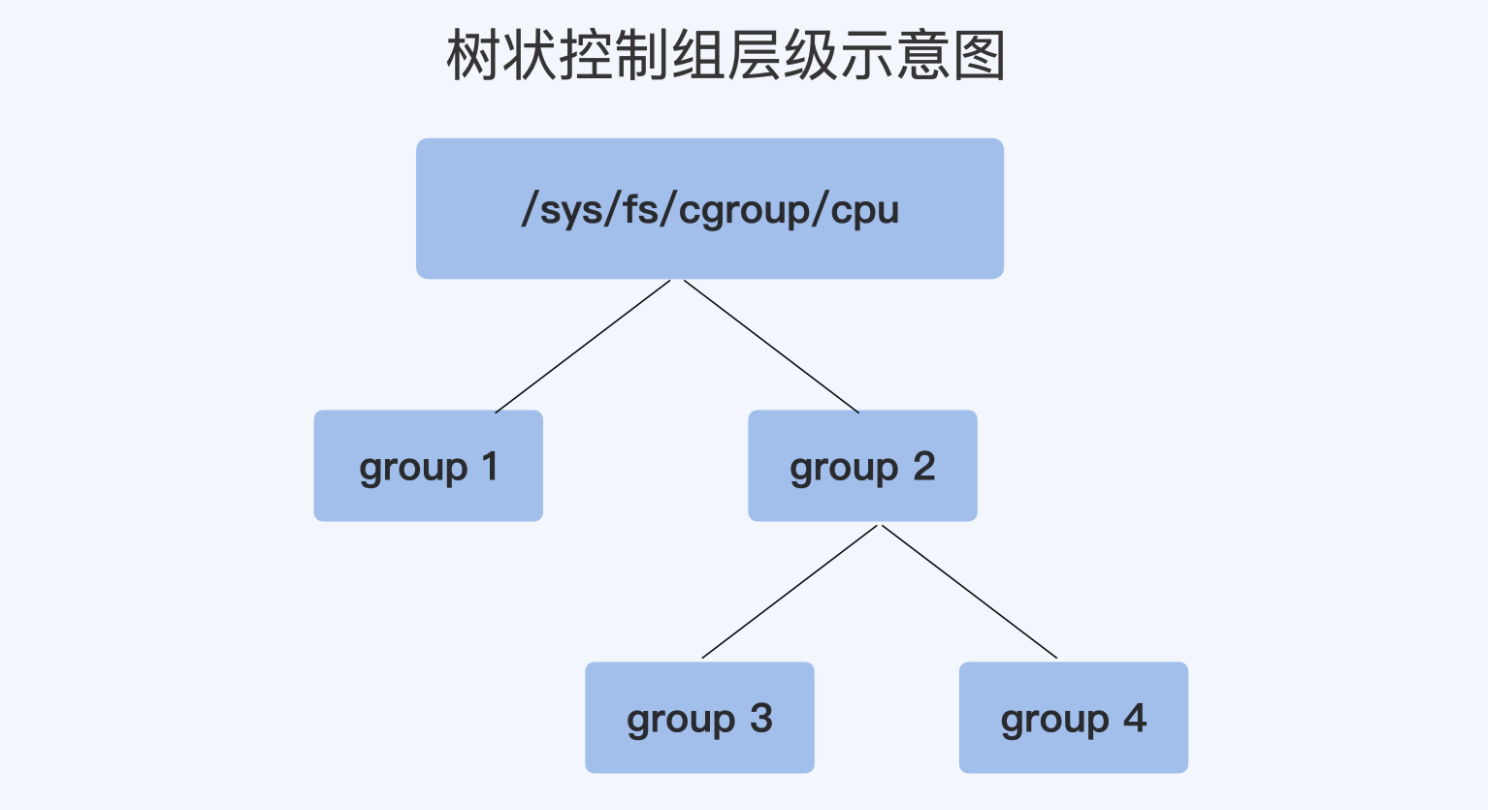
每个 Cgroup 子系统都是通过一个虚拟文件系统挂载点的方式,一般在 /sys/fs/cgroup/cpu 目录下
1 | [root@VM-0-2-centos cpu]# pwd |
文件名中的 cfs 是 Linux 中普通调度算法中的一种,CFS(Completely Fair Scheduler,即完全公平调度器),CGroup 中和 CFS 相关的参数一共三个:
cpu.cfs_period_us,调度周期,一般值是 100k,单位 microseconds,也就是 100ms
cpu.cfs_quota_us,在一个调度周期里这个控制组被允许的运行时间,比如这个值为 50000 时,就是 50ms,默认 -1 表示不限制
50ms/100ms = 0.5,这样这个控制组被允许使用的 CPU 最大配额就是 0.5 个 CPU
cpu.cfs_quota_us 和 cpu.cfs_period_us 这两个值决定了每个控制组中所有进程的可使用 CPU 资源的最大值
cpu.shares,是 CPU Cgroup 对于控制组之间的 CPU 分配比例,它的缺省值是 1024。
group3 中的 cpu.shares 是 1024,而 group4 中的 cpu.shares 是 3072,那么 group3:group4=1:3
cpu.shares 这个值决定了 CPU Cgroup 子系统下控制组可用 CPU 的相对比例,不过只有当系统上 CPU 完全被占满的时候,这个比例才会在各个控制组间起作用
Linux 中调度类型:
- 普通调度,SCHED_NORMAL
- 实时调度
- SCHED_FIFO
- SCHED_RR
进程如果设置为SCHED_FIFO 或者SCHED_RR实时调度类型,那么只要进程任务不结束,就不会把cpu资源让给SCHED_NORMAL进程。这种实时的进程,在实时性要比较高的嵌入式系统中会用到
Linux 如何计算进程 CPU 使用率和系统 CPU 使用率
进程 CPU 使用率
top 命令源码:https://gitlab.com/procps-ng/procps
Linux proc 目录文档:https://man7.org/linux/man-pages/man5/proc.5.html
top 命令会读取 /proc/[pid]/stat 中的两个值(这个 stat 文件实时输出了进程的状态信息,比如进程的运行态(Running 还是 Sleeping)、父进程 PID、进程优先级、进程使用的内存等等总共 50 多项)。
utime 是表示进程的用户态部分在 Linux 调度中获得 CPU 的 ticks,stime 是表示进程的内核态部分在 Linux 调度中获得 CPU 的 ticks,utime 和 stime 都是一个累计值,也就是说从进程启动开始,这两个值就是一直在累积增长的。
这个 ticks 可以使用 getconf CLK_TCK 取到。
ticks 就是 Linux 操作系统中的一个时间单位,在 Linux 中有个自己的时钟,它会周期性地产生中断。每次中断都会触发 Linux 内核去做一次进程调度,而这一次中断就是一个 tick。
$$
进程的 CPU 使用率 =\frac{进程的 ticks}{单个 CPU 总 ticks}*100.0
$$
进程的 ticks = (utime_2 - utime_1) + (stime_2 - stime_1);
单个CPU总 ticks = (HZ * et * 1),HZ 是 1s ticks 次数,一般是 100,et 是时间;
举例:top threads-cpu 占用 200% CPU,使用 stat 文件中的 utime 和 stime 计算一下
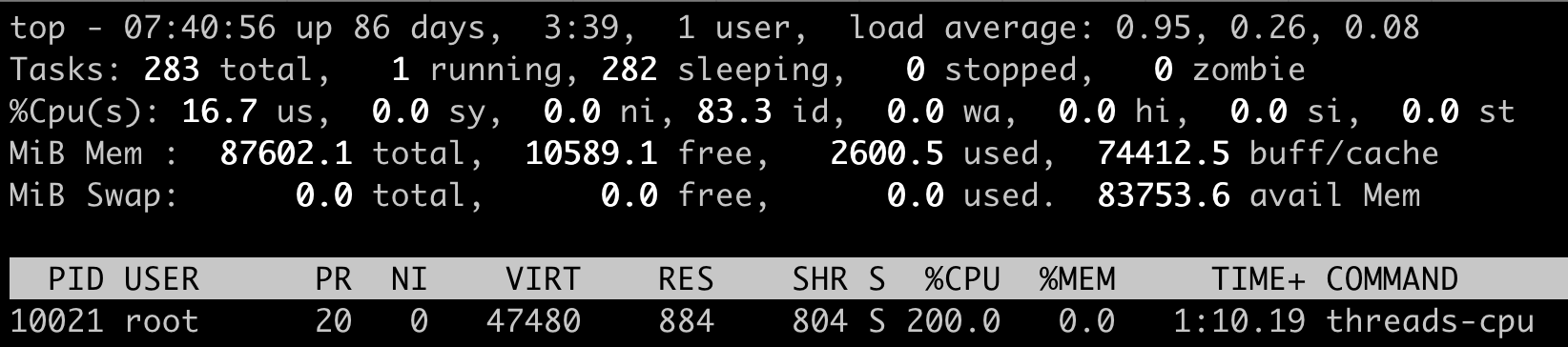

utime_1 = 399,stime_1=0,utime_2=600,stime_2=0,((600 – 399) + (0 – 0)) * 100.0 / (100 * 1 * 1) =201,也就是 201% 和 top 一致。
系统 CPU 使用率
系统级别的在 /proc/stat 文件下,10 列数据,前 8 列对应 top 中 %Cpu(s) 这一行。
user/system/nice/idle/iowait/irq/softirq/steal
同样,在 /proc/stat 里的每一项的数值,就是系统自启动开始的 ticks。那么要计算出“瞬时”的 CPU 使用率,首先就要算出这个“瞬时”的 ticks,比如 1 秒钟的“瞬时”,我们可以记录开始时刻 T1 的 ticks, 然后再记录 1 秒钟后 T2 时刻的 ticks,再把这两者相减,就可以得到这 1 秒钟的 ticks 了。

回到问题,如何正确得到容器的 CPU 开销?
对于系统总的 CPU 使用率,需要读取 /proc/stat 文件,但是这个文件中的各项 CPU ticks 是反映整个节点的,并且这个 /proc/stat 文件也不包含在任意一个 Namespace 里。对于 top 命令来说,它只能显示整个节点中各项 CPU 的使用率,不能显示单个容器的各项 CPU 的使用率。
容器 cpu cgroup 下的 cpuacct.stat 文件,包含了两个统计值,这两个值分别是这个控制组里所有进程的内核态 ticks 和用户态的 ticks。
catcpuacct.stat;sleep1;catcpuacct.stat
EOF

