
- OOM Killer
- Memory Cgroup
容器被 oom killer 干掉了
问题复现
https://github.com/chengyli/training/tree/main/memory/oom
1)编译 make mem_alloc
2)构建容器镜像 make image
3)运行测试容器 sh start_container.sh
在 start_container.sh 中将容器的 Cgroup 内存上限设置为 512MB。
现象:
容器启动 30s 后会不断申请内存,当申请的内存超过 512MB 时,容器 exited。
使用 docker inspect [容器ID] | grep -i Status -A 10 可以看到 "OOMKilled: true"。
OOM Killer
out of memory killer,在 Linux 系统里如果内存不足时,就需要杀死一个正在运行的进程来释放一些内存。
申请内存调用
malloc()为什么内存不够不返回错误/失败?而要去杀死正在运行的进程?Linux 进程的内存申请策略相关。
Linux 允许进程在申请内存的时候是 overcommit 的,允许申请超过实际物理内存上限的内存。
每次 malloc 申请的是虚拟地址,系统只给了一个地址范围,没有写入数据,所以并不会真正使用。
overcommit 的内存申请模式可以有效提高系统的内存利用率。
选择被杀进程的标准
Linux 内核里 oom_badness() 定义了选择进程的标准。
1)进程已使用的物理内存页面数
2)每个进程的 OOM 校准值 oom_score_adj,每个进程都有一个接口文件 /proc/<pid>/oom_score_adj,取值范围 [-1000, 1000]
具体计算方法:值越大被 OOM kill 的几率也越大!
$$
系统总可用页面数 * OOM校准值 + 已使用的物理页面数
$$
1 | adj = (long)p->signal->oom_score_adj; |
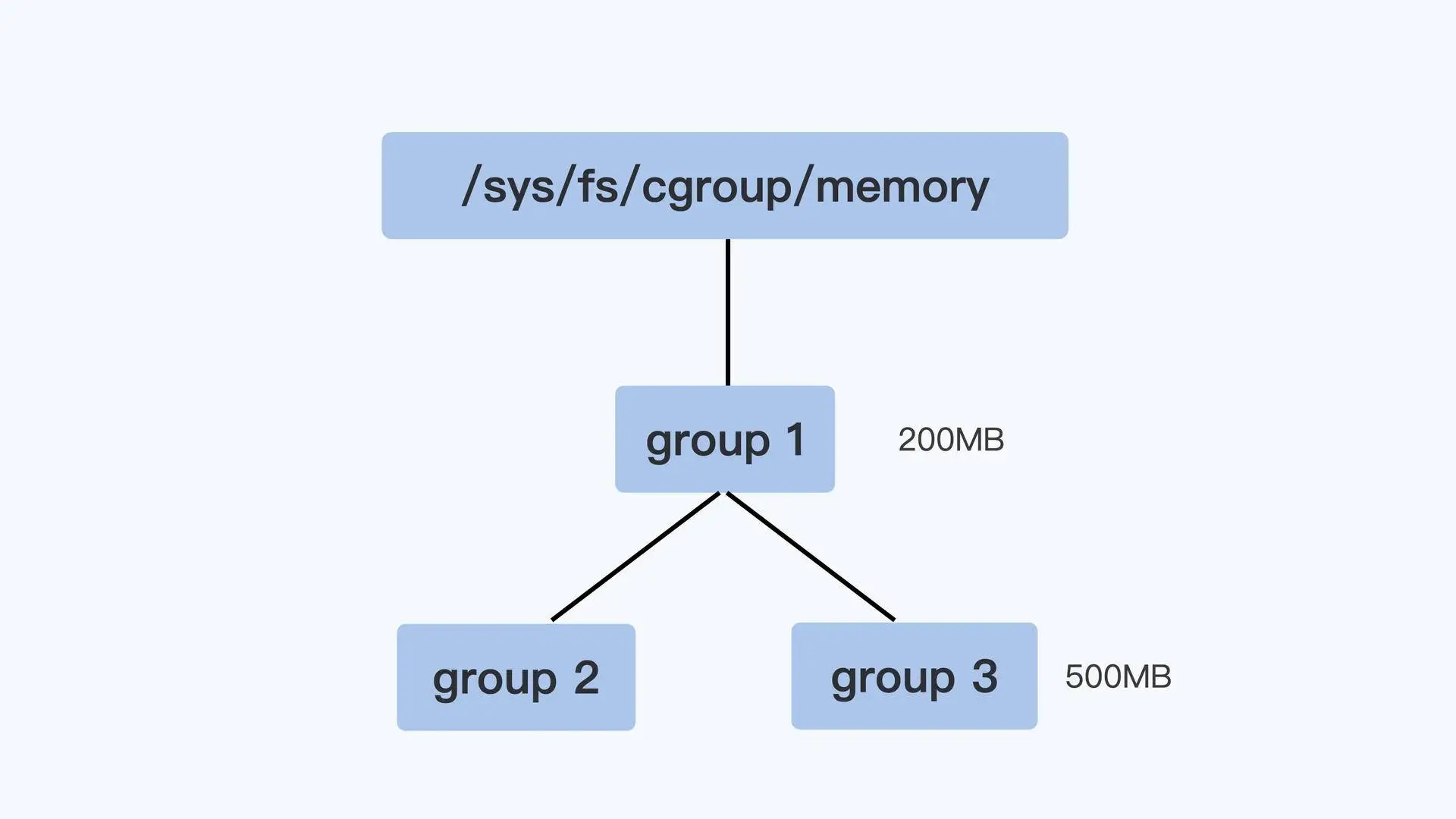
Memory Cgroup
挂载点一般在 /sys/fs/cgroup/memory。
Memory Cgroup 各配置说明:https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v1/memory.html
跟 OOM 最相关的 3 个参数:
memory.limit_in_bytes,控制组最大内存使用量
memory.oom_control,当控制组中的进程内存使用达到上限时,是否触发 OOM Killer
缺省值为会触发控制组内的 OOM Killer,和系统的 OOM Killer 功能差不多,差别是杀死进程的选择范围
You can disable the OOM-killer by writing “1” to memory.oom_control file, as:
#echo 1 > memory.oom_control
这会导致正在申请物理内存页面的进程 hang/wait!!!
memory.usage_in_bytes,只读,当前控制组里所有进程实际使用的内存总和
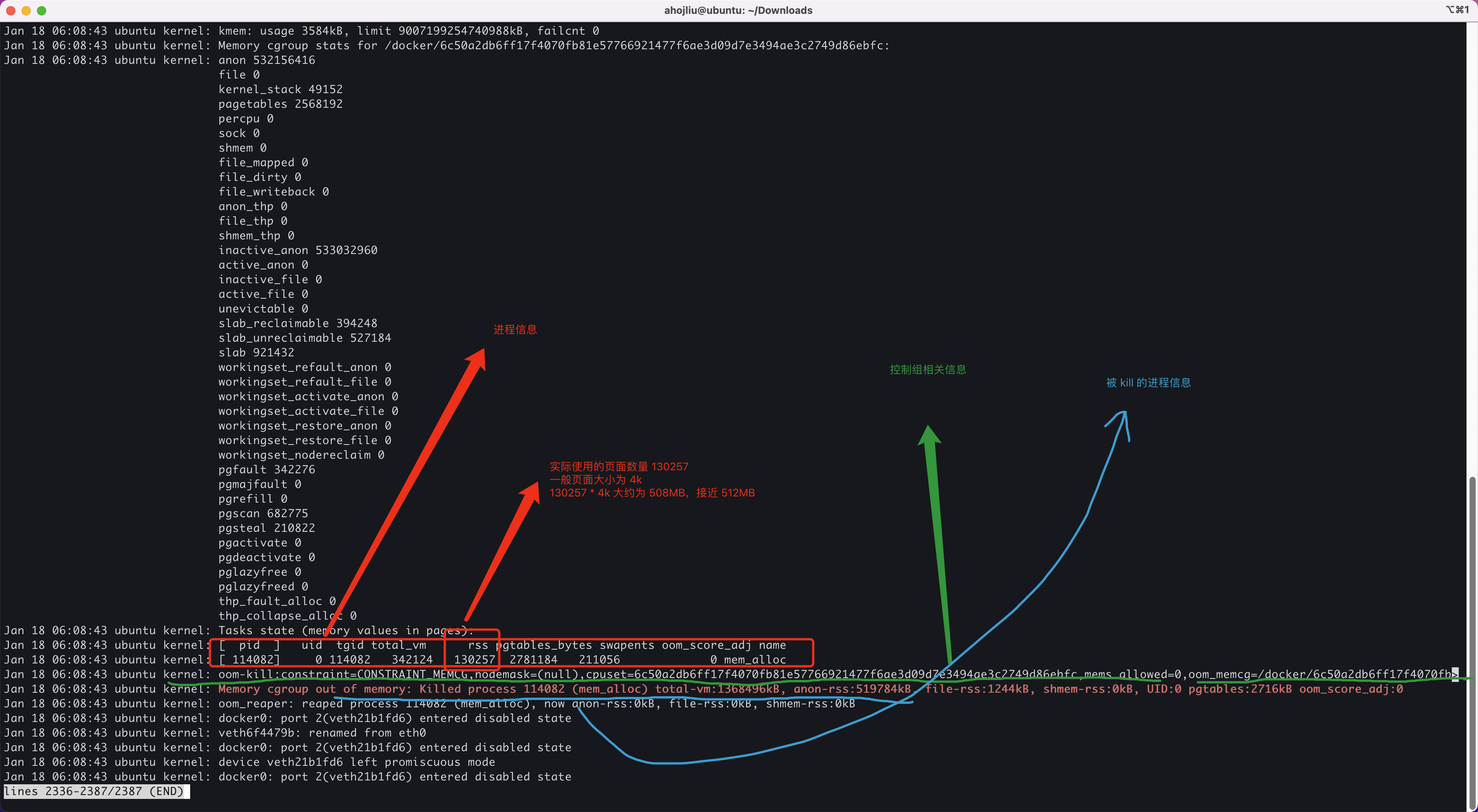
如何快速定位容器 OOM?
查看内核日志 journalctl -k 或者直接查看日志文件 /var/log/message。
当容器发生 OOM Kill 时候会输出以下相关信息:
Linux 用户态内存类型
内核需要分配内存给页表、内核栈、slab,也就是内核各种数据结构的 Cache Pool;
用户态进程里的堆、栈、共享库的内存、文件读写的 Page Cache。
RSS
Resident Set Size,就是进程真正申请到物理页面的内存大小。
RSS 包含了进程的代码段、栈、堆、共享库内存。
在 top 命令中显示的是 RES(Resident 缩写)。
具体每一部分的 RSS 内存大小可以查看 /proc/[pid]/smaps 文件。
先 malloc 了 100MB 内存(堆上),然后使用 top 查看此进程内存使用情况:
虚拟地址空间 VIRT 使用了约 106728KB ≈ 100MB,但实际物理内存 RSS 只有 688KB。
1 | p = malloc(100 * MB); |

在向申请的空间里写入 20MB 数据,再次查看:
VIRT 没变,RSS 变成了 21432KB ≈ 20MB。
1 | sleep(30); |

Page Cache
每个进程除了各自独立分配到的 RSS 内存外,如果进程对磁盘上的文件做了读写操作,Linux 还会分配内存,把磁盘上读写到的页面存放在内存中,这部分的内存就是 Page Cache。
Page Cache 的主要作用是提高磁盘文件的读写性能,因为系统调用 read() 和 write() 的缺省行为都会把读过或者写过的页面存放在 Page Cache 里。
Linux 的内存管理有一种内存页面回收机制(page frame reclaim),会根据系统里空闲物理内存是否低于某个阈值(wartermark),来决定是否启动内存的回收。
Memcgroup 和 RSS、Page Cache
Linux 内核代码:mem_cgroup_charge_statistics(),可以看到 Memory Cgroup 也的确只是统计了 RSS 和 Page Cache 这两部分的内存。Cgroup 中的 memory.stat 可以看到当前控制组里各种内存类型的实际的开销。
1 | memory.usage_in_bytes = RSS + Page Cache |
当控制组里的进程需要申请新的物理内存,而且 memory.usage_in_bytes 里的值超过控制组里的内存上限值 memory.limit_in_bytes,这时 Linux 的内存回收(page frame reclaim)就会被调用起来。
free里的cache/buffer就是page cache, 早期Linux文件相关的cache内存分buffer cache和page cache, 现在统一成page cache了。 shared内存一般是tmpfs 内存文件系统的用到的内存。

